一、键和值的组织
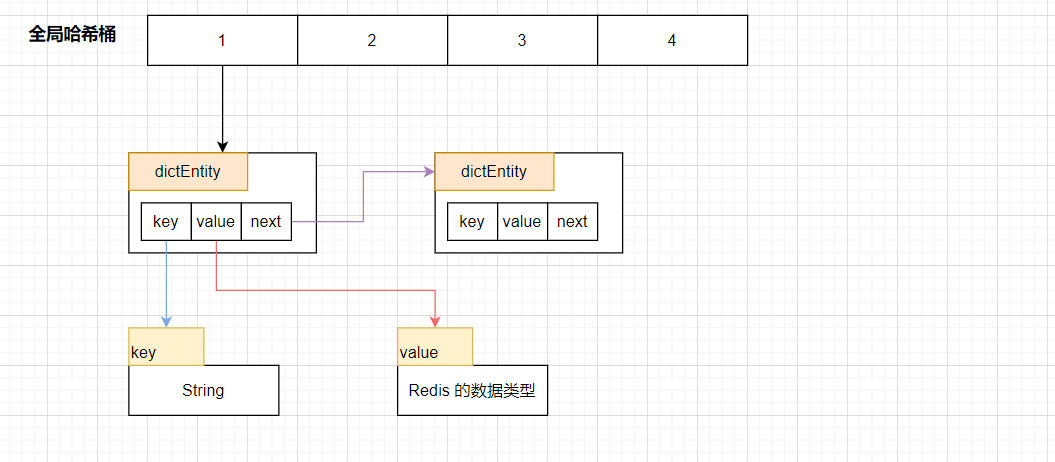
1.1 全局哈希表
对于 Redis 来说,它能够以 O(1) 的形式来找到某一个具体的键值对,内部使用了一个 **哈希表 **来保存所有的键值对,其中,key 只能为字符串,value 可以有多个数据类型组成,里面存储的元素并不是值本身,而是指向具体值的指针
1.2 哈希冲突
使用了哈希表,就不得不面临是哈希冲突的问题,Redis中解决哈希冲突的方式,是 链式哈希。
最好情况之下就是用O(1)的时间复杂度就能够找到一个元素,但是如果说这条链子的长度过长,就会造成查询这个键值对为 O(N),为了解决这个问题,哈希表就需要考虑扩容的问题,让元素更加散列的分布,让这条链,没有必要这么长。但是当 Redis 中存储的元素过多,一次性进行扩容的话,就会导致 Redis 卡顿,为了解决这个问题,Redis 采用 rehash 的方式。
在 Redis 中默认使用了两个哈希表,rehash 的具体步骤如下:
- 给哈希表2分配更多的空间
- 把哈希表1之中的元素重新映射并拷贝到哈希表2之中
- 释放哈希表1的空间
到这样,我们就可以把哈希表1切换到哈希表2之中,用增大的哈希表保存更多的数据,而原来的哈希表作为下一次的 rehash 备份使用。不过这个时候我们能够发现,对于 步骤二这个是一个非常耗时的操作,并且这个过程如果不能够进行其余键值对的写入,对于 Redis 来说不能够接受。为了避免这个问题,Redis 采取** 渐进式 rehash** 的方式,也就是说逐步完成第二个步骤,重新映射的过程。Redis 仍然能够正常处理客户端的请求,每处理一个请求的时候,从哈希表中的第一个索引开始,顺带着将这个索引的所有的 entries 拷贝到哈希表2之中。等处理下一次请求的过程之中,在顺带将下一个索引的元素执行这样的操作。通过这样就巧妙的避免了一次性大量拷贝带来的开销。除了键值对的操作来进行数据迁移,Redis 本身还会有一个定时任务来执行 rehash。
二、RedisObject
Redis 为我们封装了多种数据结构,如 Stirng 类型,Hash 类型,List 类型,Set 类型,ZSet 类型。为了方便操作和维护,Redis 基础之上,又封装了 RedisObject。
对应的定义如下:
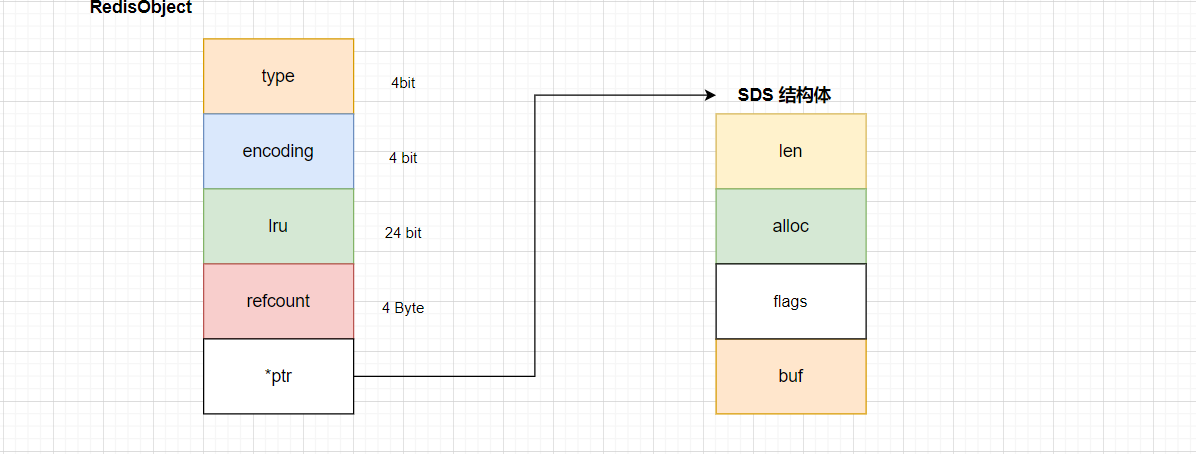
struct redisObject {
// 类型
unsigned type:4;
// 编码,当前对象底层存储所使用的数据结构
unsigned encoding:4;
// 最后一次的访问时间
unsigned lru:LRU_BITS;
// 引用次数
int refcount;
// 指向实际的对象
void *ptr;
};对应字段占用的空间数如下:

type 字段是用来存储对象的类型的,其中在 Server.h 中,定义了 redis 中支持的 数据结构的类型,包括,String 类型,List 类型,Set 类型,Sorted Set 类型,Hash 类型。这几个类型是 Redis 为我们封装好,直接使用的,每种数据类型底层还采用了其他的数据结构来进行存储。具体采用哪种数据结构,则在 encoding 字段存储。
三、基本数据类型
3.1 String 类型
String 是最基本的 key-value结构,key 是唯一标识,value 是具体的值,value其实不仅是字符串, 也可以是数字(整数或浮点数)
3.1.1 常用命令
# 设置一个key - value ,如果说key存在,就进行数据的更新
1. set key value
# 根据key获取对应的value
2. get key
# 一次设置多个key,value
3. mset key1 value1 key 2 value2
# 一次获取多个key对应的value值,实际上是执行了 n 次的 get命令
4. mget key1 key2
# 获取原始的key的值,同时设置新的值
5. getset key newValue
# 获取对应 key 的 value 的长度
6. strlen key
# 为对应的key的value追加内容
7. append key value
# 设置一个key存活的有效期,时间是秒
8. setex key 超时时间 value
# 设置一个key存活的有效期
9. psetex key 超时时间 value
,
# 截取value的内容
10. getrange key start end
# 存放不做任何的操作,不存在就进行添加
11. setnx key name
# 将key存储的数字值加一,返回自增之后的结果。如果值不是整数,就会返回错误
12. incr key
# 将key存储的数字值减一
13. decr key
# 设置指定位置的字符
14. setrange key offset value3.1.2 底层数据结构
存储不同类型的数据,它的内部实现是不同的。比如说:
1) 保存64位的有符号整数的时候,String类型会把他保存为一个 8 字节的Long类型整数,这种方式通常称之为** int编码方式**
2) 保存的数据中包含字符的时候,String类型就会用 简单动态字符串(SDS)结构体 来保存。一个 SDS 结构体,包含如下内容:
buf:字节数组,用来保存实例数据,为了表示字节数组的结束,Redis会自动在数组的最后加上“\0”,这就会额外占用一个字节的开销。len:表示 buf 的已用长度alloc:表示 buf 的实际分配长度
为了存储不同长度的字符串, redis 定义了不同的 SDS 结构体的定义。如:sdshdr5、sdshdr8、sdshdr16、sdshdr32、sdshdr64。这几种类型的区别仅仅区分在 len、alloc 字段的类型之上,并且加入了 flag 字段进行区分不同的类型,其中低 3 位用来存储类型,高 5 位是预留的。不过 sdshdr5 并没有被使用。

除了 SDS 之外,上文,我们还提到了 RedisObject,所以最终的数据结构为:
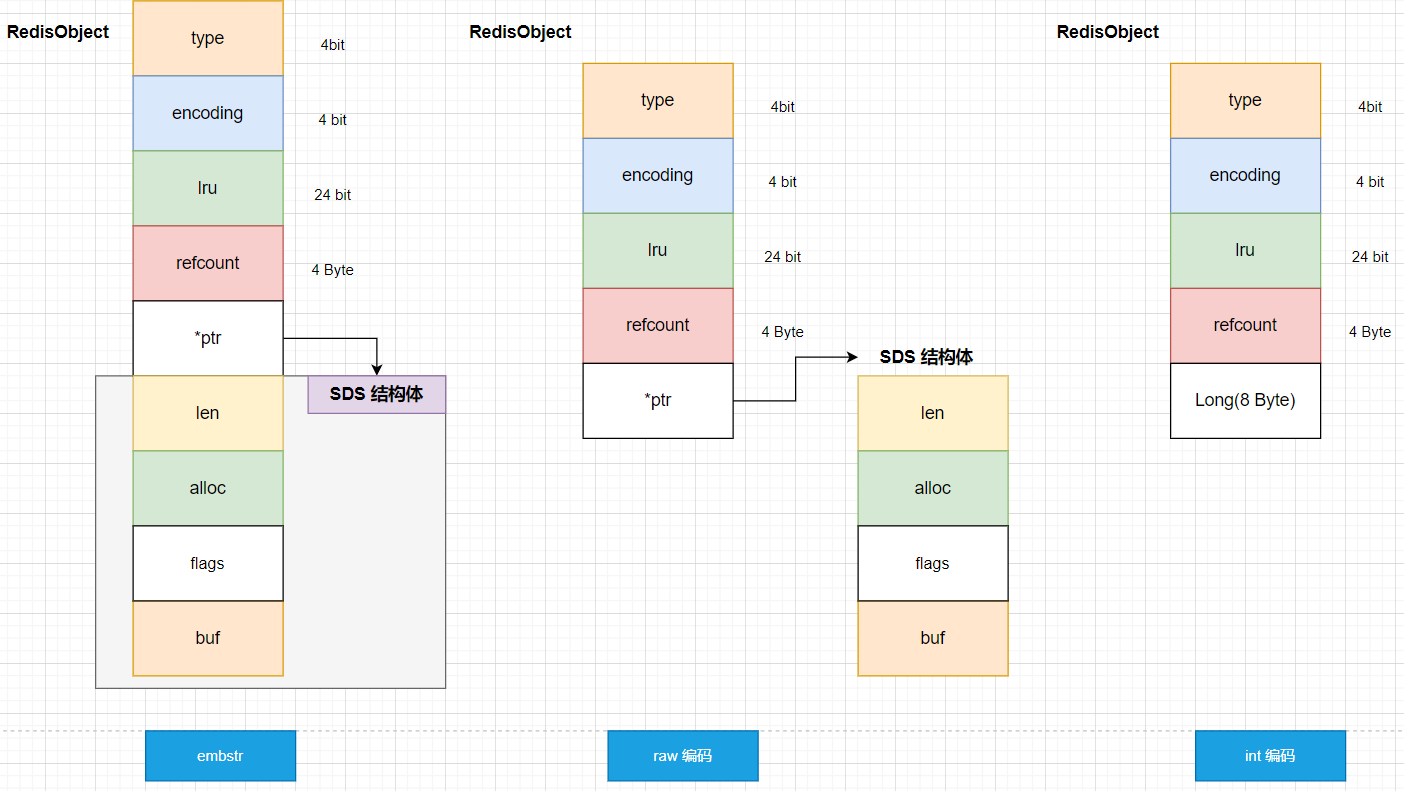
为了节约内存空间,Redis 对 Long 类型 和 SDS 的内存布局进行了专门的设计。
- 保存的是 Long 类型的整数时,RedisObject 中的指针直接赋值为整数数据,也称之为
int编码 - 存放的是字符串类型的数据时
- 字符串小于等于 44 字节,RedisObject中的元数据、指针和SDS是一块连续的内存区域,这样就可以避免内存碎片,称之为
embstr编码 - 如果大于 44 字节,会单独为 SDS 申请一块空间,称之为
raw编码
- 字符串小于等于 44 字节,RedisObject中的元数据、指针和SDS是一块连续的内存区域,这样就可以避免内存碎片,称之为
为了验证,我们可以通过下面这种方式进行验证
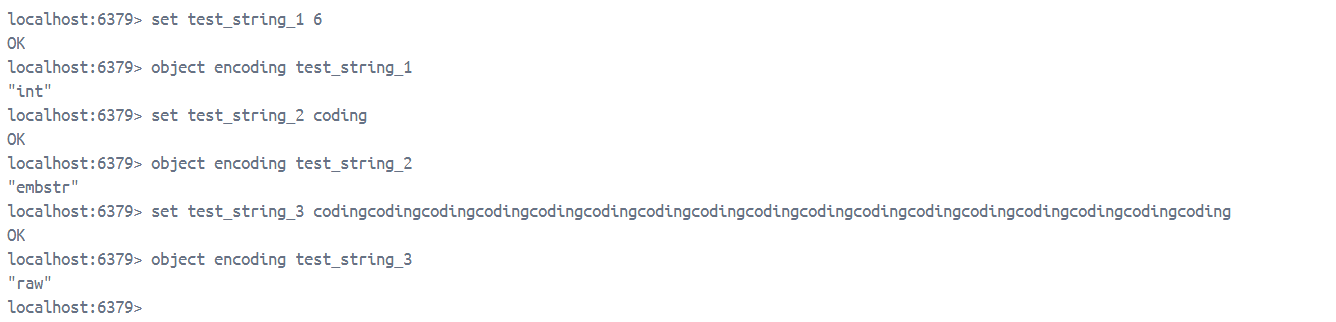
那么,为什么 Redis 之中要自定义 SDS 来存储字符串呢?
主要原因在于:C 语言的字符串是通过字符数组来实现的,为了表示字符串的结束,他会在字符数组的最后面记录一个 \0 ,用来标识字符串结束了,如果字符串之中就是包含这个字符,就会被截断,这就造成了非二进制安全。但是这样做,就会导致字符串之中存储的内容就有了限制,并且如果要获取字符串的长度每次都需要从头开始遍历,直到找到 \0 为止。
3.2 List 类型
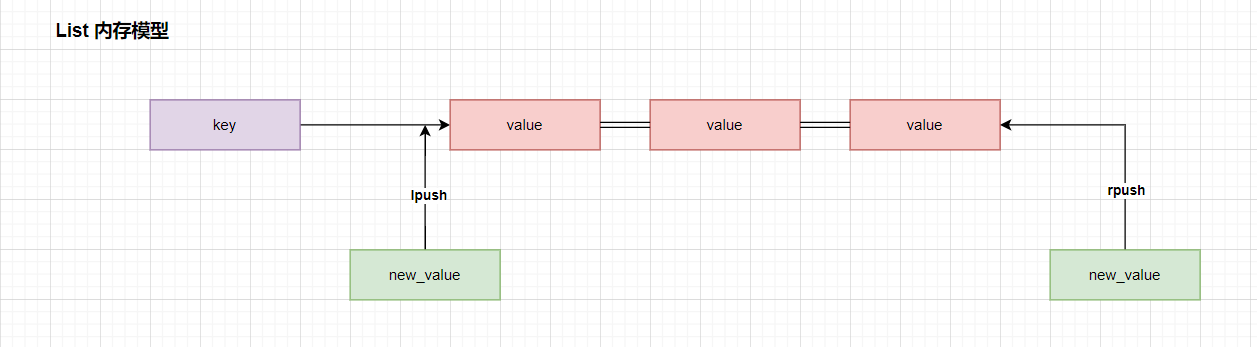
3.2.1 常用命令
# 将某个值加入到一个key列表头部,添加多个value,每个value都是lpush一遍
1. lpush key value [value2 value3 value4 value5...valuen]
# 同lpush,但是必须要保证这个key存在
2. lpushx key value
# 将某个值加入到一个key列表末尾
3. rpush key value
# 同rpush,但是必须要保证这个key存在
4. rpushx key value
# 返回和移除列表左边的第一个元素
5. lpop key
# 返回和移除列表右边的第一个元素
6. rpop key
# 获取某一个下标区间内的元素
7. lrange key startIndex endIndex
# 获取列表元素个数
8. llen key
# 获取某一个指定索引位置的元素
9. lindex key index
# 设置某一个指定索引的值(索引必须存在)
10. lset key index value
# 删除重复元素
11. lrem key count element
# 在某一个元素之前,之后插入新元素
12. linsert key before|after element value3.2.2 底层数据结构
Redis 列表对象的底层使用 quickList。这种数据结构在 Redis 3.2 版本中引入的。在以前的版本之中,List 类型的底层数据结构是由,双向链表或者压缩列表来实现的,这样做的主要原因在于,当元素个数少的时候,使用压缩列表可以有效的节省空间,随着元素数量的增加,压缩列表修改元素的时候,必须要重新分配空间,这无疑会影响 Redis 的执行效率。
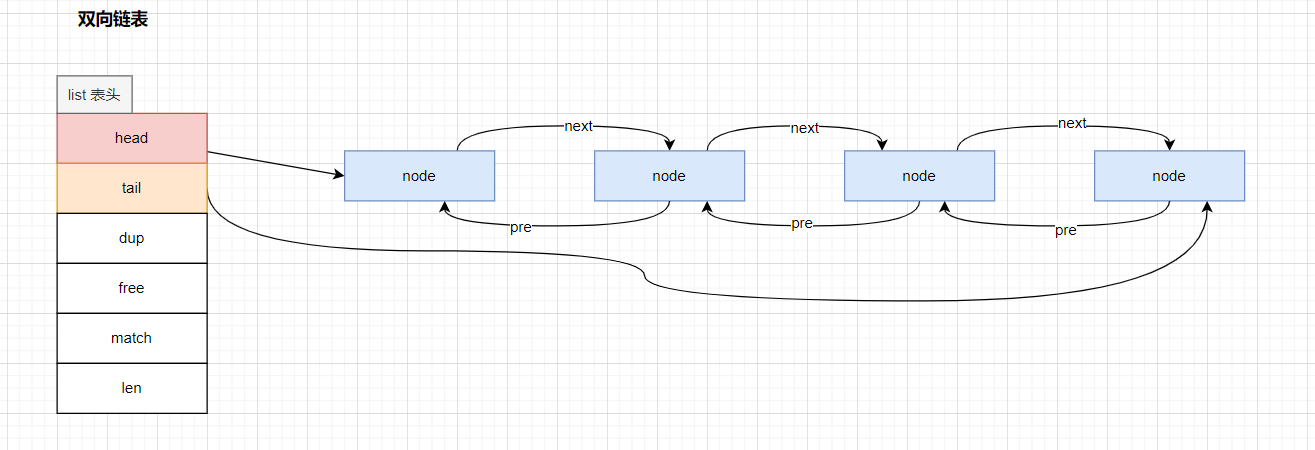
3.2.2.1 双向链表
Redis 3.2 之前的版本,使用的是双向非循环链表,为了方便的操作链表,在 Redis 3.2 版本之后,映入了 List 表头,在表头之中,引入了指向头结点的 head 指针,尾结点的 tail 指针,并且加入了存储链表长度的 len 字段。
3.2.2.2 压缩列表
压缩列表,本质上就是一个字节数组,主要的设计目的是为了节约内存。
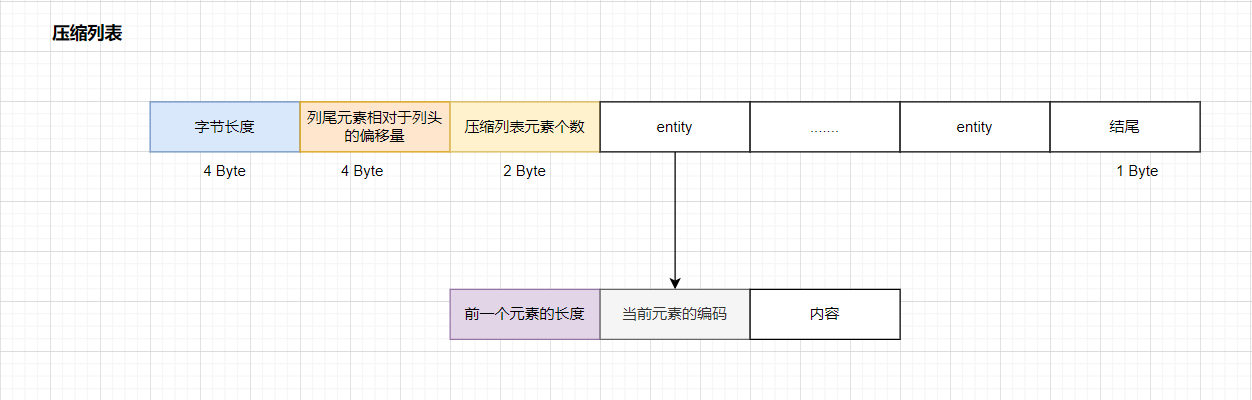
1)前一个元素的长度
- 对于每一个 Entity,存储前一个元素的长度,占用 1Byte 或者 5 Byte
- 当前一个元素的长度小于 254 Byte 的时候,使用 1Byte
- 当前一个元素的长度大于等于 254 Byte 的时候, 采用 5 Byte,此时第一位是固定的 0xFE,后面的 4 个字节才真正的表示前一个元素的长度。
- 存储目的是为了实现压缩列表从尾到头的遍历。因为如果知道了当前元素的位置,则 当前元素的起始位置 - 前一个元素的长度 = 前一个元素的起始位置
- 连锁更新:由于压缩列表会存储前一个元素的长度,如果我们想删除某一个位置的元素,就会导致每次元素的扩展都会导致内存被重新分配。
2)当前元素的编码:content 字段存储的数据类型。
3.2.2.3 quickList
quickList 是 Redis 3.2 引入的数据结构,能够在空间和时间效率上得到很好的折中。quickList 是一个双向链表,不过链表的每一项都是压缩列表。
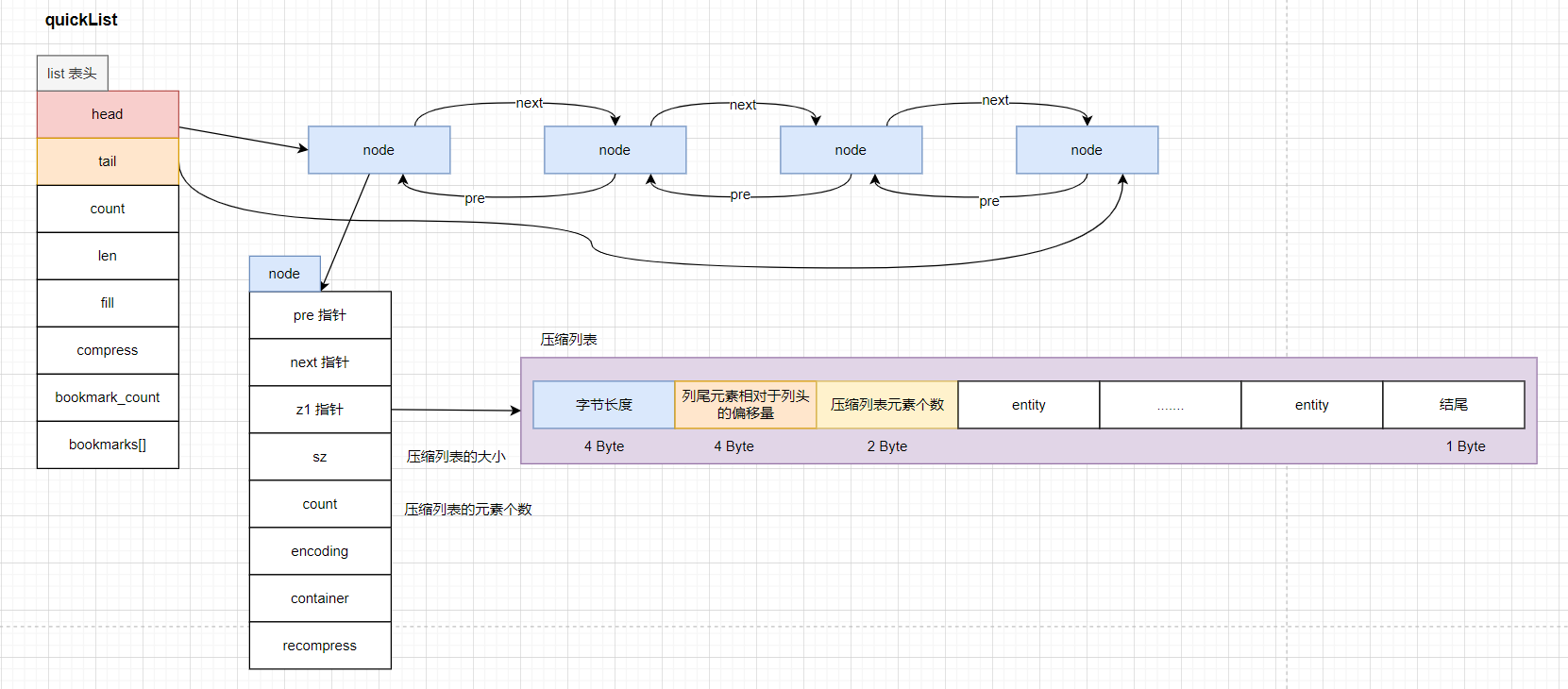
此时的 node 节点,相比于双向链表进行了一定的扩展,我们首先来解释一下这几个字段:
- encoding:是否采用 LZF 算法压缩
压缩列表,1 表示不压缩,2 表示压缩 - container:节点采用的容器类型,1 表示 none,2 表示使用压缩列表
- recompress:节点是否被标记为压缩过。
3.3 Hash类型
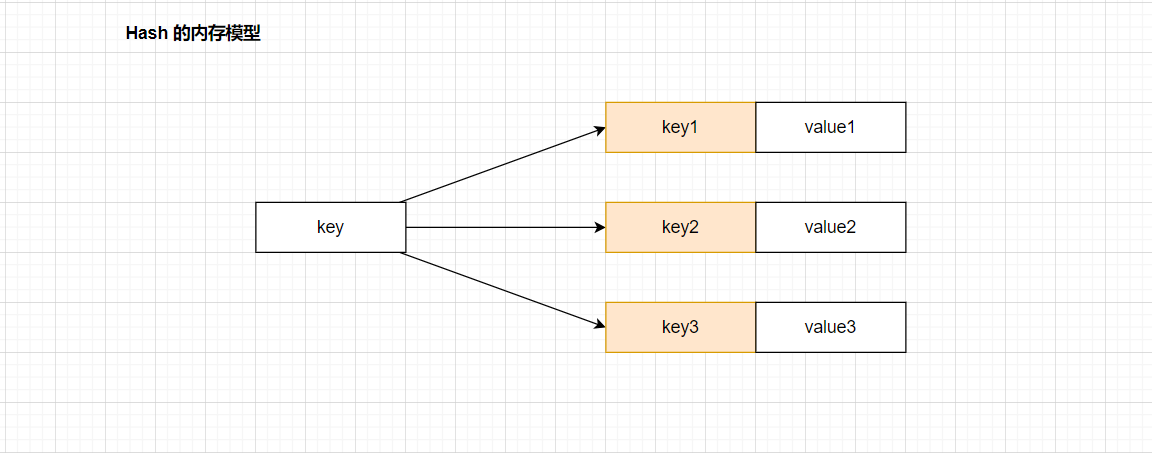
Hash类型,value是一个map结构,value中的每一项都存在key和value,并且这里的key是无序的。这种方式比较适合于存储对象。
3.3.1 常用命令
# 设置一个key/value对
1. hset key field value
# 获得一个key对应的value
2. hget key field
# 获得所有的key/value对
3. hgetall key
# 删除某一个key/value对
4. hdel key field
# 判断一个key是否存在
5. hexists key field
# 获得所有的key
6. hkeys key
# 获得所有的value
7. hvals key
# 设置多个key/value
8. hmset
# 获得多个key的value
9. hmget
# 设置一个不存在的key的值
10. hsetnx
# 为value进行加法运算
11. hincrby key field n
# 为value加入浮点值
12. hincrbyfloat3.3.2 底层数据结构
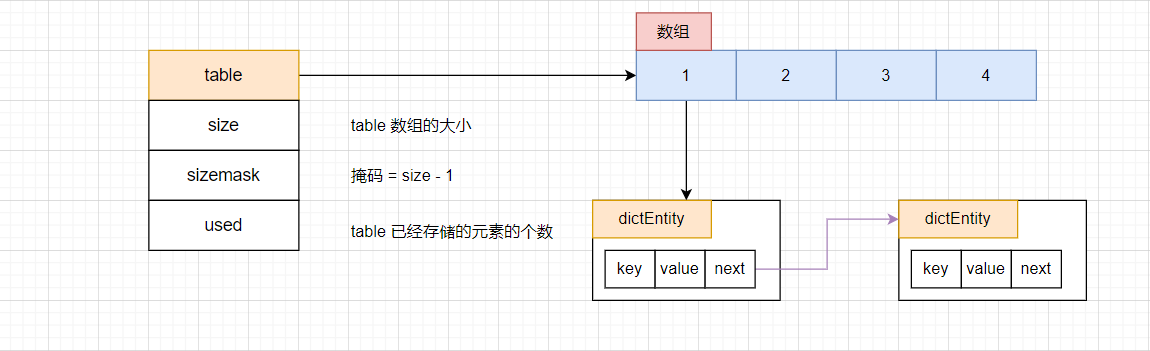
如果使用 Hash 表,必然会面临两个问题
- 哈希冲突:在 Redis 中,哈希表采用的是链式哈希,当有冲突的时候,实际上是将元素接在链表之中的。
- 另一个就是 扩容。与第一章节是一致的
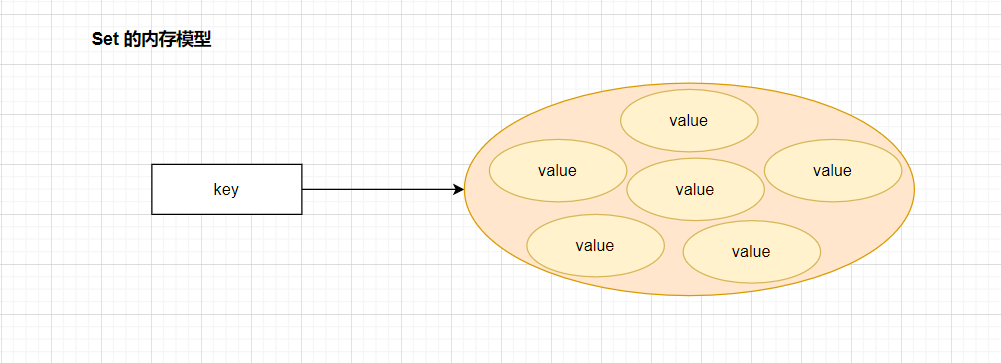
3.4 Set 类型
Set集合只能存储 ** 的元素,并且元素是 **的。
3.4.1 常用命令
# 为集合添加元素
sadd
# 显示集合中所有元素 无序
smembers
# 返回集合中元素的个数
scard
# 随机返回一个元素 并将元素在集合中删除
spop
# 从一个集合中向另一个集合移动元素 必须是同一种类型
smove
# 从集合中删除一个元素
srem
# 判断一个集合中是否含有这个元素
sismember
# 随机返回元素
srandmember
# 去掉第一个集合中其它集合含有的相同元素
sdiff
# 求交集
sinter
# 求和集
sunion3.4.2 底层数据结构
Set 类型,底层基于 哈希表 与 整数集合 实现。当 Redis 集合类型的元素都是整数,并且都处于 64 位有符号整数范围之内的时候,使用整数集合,其余情况都是基于 哈希表来存储数据的。
在两种情况之下,底层编码会发生变化
- 元素个数超过一定数量,即时元素个数仍然为整形,也会转为哈希表
set-max-intset-entries 512- 增加非整形的变量
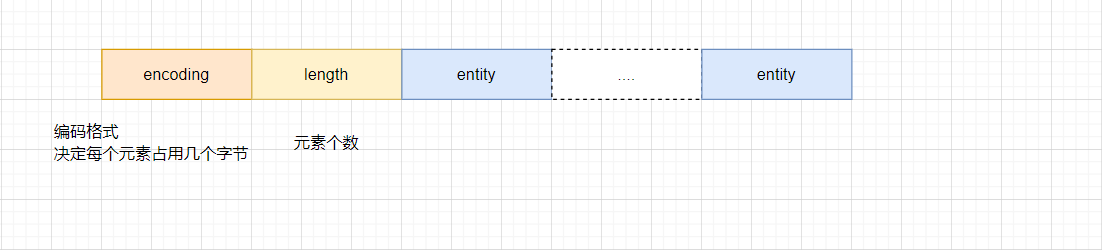
对于整数集合,对应的结构如下:
3.5 ZSet 类型
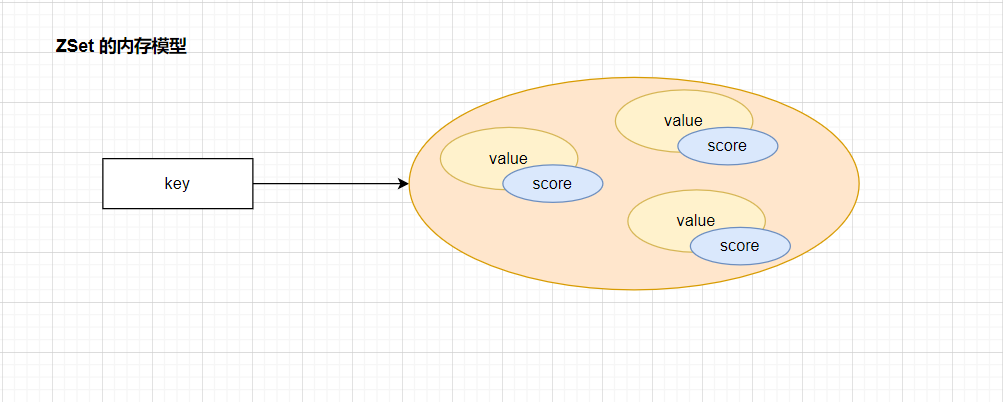
Zset 是 可排序的set集合 排序 不可重复 。每个元素都带有一个“分数”,是根据这个分数进行的排序。所以添加元素的时候,必须添加一个分数。
3.5.1 常用命令
# 添加一个有序集合元素
1. zadd key score value [score value score value score value...]
# 返回集合的元素个数
2. zcard key
# 返回一个范围内的元素 zrange 升序 zrevrange 降序
3. zrange key start end [withscores]
# 按照分数查找一个范围内的元素
4. zrangebyscore key min max [withscores] [limit startIndex endIndex]
# 返回排名
5. zrank key value
# 倒序排名
6. zrevrank key value
# 显示某一个元素的分数
7. zscore key value
# 移除某一个元素
8. zrem key value
# 给某个特定元素加分
9. zincrby key num value3.5.2 底层数据结构
Zset 类型的底层数据结构是由 ****实现的
在链表之中,即时里面的元素是有序的,如果想寻找某个元素,也只能从头遍历到尾。如果想提供查询效率,我们可以在原有链表的基础之上,添加一层索引。

如果我们现在想查询 6 ,在原有的链表上,我们需要将链表从头遍历到尾。添加了索引之后,我们需要遍历索引层,看 6 这个节点,实际上位于那个数据段之中。遍历到 1 -> 3 -> 5,然后通过索引层的 5 的 指针定位到原来的链表,继续遍历,寻找 6.
假设链表中有 N 个元素,每两级抽取一层索引,则第 K 层的索引个数为:n / 2<sup>k</sup>。假设索引的高度为 H,最高层的索引有两个节点,则 n / 2<sup>h </sup>= 2,进而 h = log<sub>2</sub>n / 2,即 log<sub>2</sub>n - 1。最后,还需要遍历一层链表,则实际上一共有:log<sub>2</sub>n 层。如果每层遍历 m 个节点,则实际上需要遍历 m * log<sub>2</sub>n个节点。
所以,跳表的时间复杂度为:O(log<sub>2</sub>n)。但是维护一个跳表,实际上需要维护一套索引结构,空间复杂度就很高。
五、扩展数据类型
5.1 HyperLogLog
HyperLogLog 是一种用于统计基数的数据集合类型,他的最大的优势就在于,当集合元素数量非常大的时候,他计算基数所用的空间总是固定的,而且还很小。对于它来讲,只需要 12 kb 的内存,就可以计算 264 个元素的基数,但是他的统计规则是通过概率来完成的,标准误差率是 0.81 %。
常用命令如下:
# 添加元素
localhost:6379> pfadd test_hyperLogLog_1 user1 user2 user3
(integer) 1
# 统计集合元素的个数
localhost:6379> pfcount test_hyperLogLog_1
(integer) 35.2 GEO
5.3 Stream
stream 是 Redis 提供的消息队列的设计。
- XADD:插入消息,保证有序,可以自动生成全局唯一 ID
- XREAD:用于读取消息,可以按照 ID 读取数据
- XREADGROUP:按照消费者组读取消息